什么叫一致性哈希,通常用来解决什么问题?
小课堂
分享人:赵君钊
1.背景介绍
2.知识剖析
3.常见问题
4.解决方案
5.编码实战
6.扩展思考
7.参考文献
8.更多讨论
1.背景介绍
在了解一致性哈希算法之前,先了解一下一致性哈希算法的应用场景,在做缓存集群时,为了缓解服务器的压力,会部署多台缓存服务器,把数据资源均匀的分配到每个服务器上,分布式数据库首先要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整体数据的一个子集。
数据分布通常有哈希分区和顺序分区两种方式
- 顺序分布:数据分散度易倾斜、键值业务相关、可顺序访问、不支持批量操作
- 哈希分布:数据分散度高、键值分布业务无关、无法顺序访问、支持批量操作
2.知识剖析
节点取余分区
普通哈希算法,使用特定的数据,如Redis的键或用户ID,再根据节点数量N使用公式:hash(key)% N 计算出哈希值,用来决定数据映射到哪一个节点上。
优点
这种方式的突出优点是简单性,常用于数据库的分库分表规则。一般采用预分区的方式,提前根据数据量规划好分区数
缺点
当节点数量变化时,如扩容或收缩节点,数据节点映射关系需要重新计算,会导致数据的重新迁移。所以扩容时通常采用翻倍扩容,避免 数据映射全部被打乱,导致全量迁移的情况,这样只会发生50%的数据迁移。
一致性哈希算法
一致性哈希的目的就是为了在节点数目发生改变时尽可能少的迁移数据,将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash 后会顺时针找到临接的存储节点存放。而当有节点加入或退 时,仅影响该节点在Hash环上顺时针相邻的后续节点。
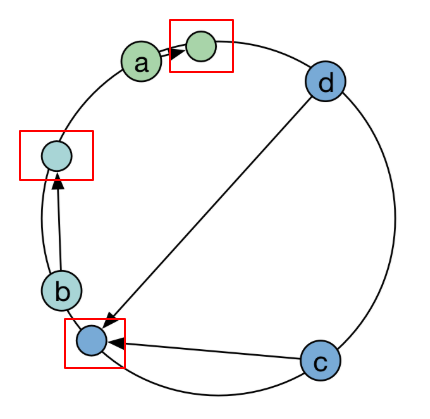
优点
加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。
缺点
数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果。
虚拟槽分区
本质上还是第一种的普通哈希算法,把全部数据离散到指定数量的哈希槽中,把这些哈希槽按照节点数量进行了分区。这样因为哈希槽的数量的固定的,添加节点也不用把数据迁移到新的哈希槽,只要在节点之间互相迁移就可以了,即保证了数据分布的均匀性,又保证了在添加节点的时候不必迁移过多的数据。
3.常见问题
4.解决方案
5.编码实战
6.扩展思考
7.参考文献
8.更多讨论
鸣谢
感谢大家观看
BY:赵君钊