redis缓存集群介绍
分享人:鲁伯良
目录
1.背景介绍
2.知识剖析
3.常见问题
4.解决方案
5.编码实战
6.扩展思考
7.参考文献
8.更多讨论
1.背景介绍
redis
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。2.知识剖析
redis性能
如下图所示
我们在碰到需要执行耗时特别久,且结果不频繁变动的SQL,就特别适合将运行结果放入缓存。这样,后面的请求就去缓存中读取,使得请求能够迅速响应br>

(二)并发
如下图所示,在大并发的情况下,所有的请求直接访问数据库,数据库会出现
连接异常。这个时候,就需要使用redis做一个缓冲操作,让请求先访问到
redis,而不是直接访问数据库。

哨兵模式 在redis3.0以前的版本要实现集群一般是借助哨兵sentinel工具来监控master节点的状态,如果master节点异常,则会做主从切换,将某一台slave作为master,哨兵的配置略微复杂,并且性能和高可用性等各方面表现一般,特别是在主从切换的瞬间存在访问瞬断的情况
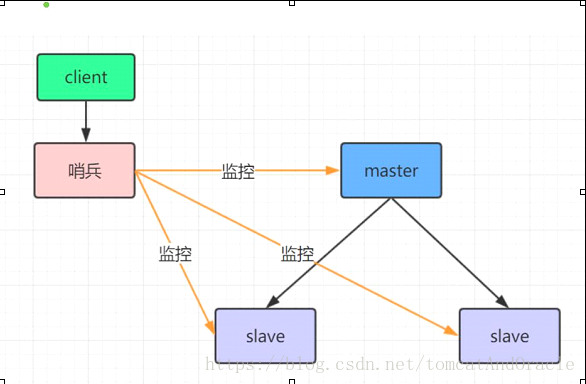
高可用集群
redis集群是一个由多个主从节点群组成的分布式服务器群,它具有复制、高可用和分片特性。Redis集群不需要sentinel哨兵也能完成节点移除和故障转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展,据官方文档称可以线性扩展到1000节点。redis集群的性能和高可用性均优于之前版本的哨兵模式,且集群配置非常简单
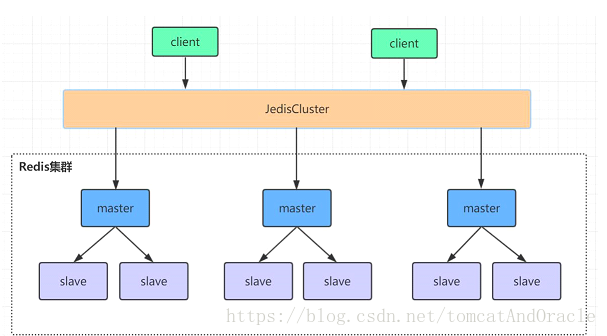
集群搭建
1.安装好redis3.0以上版本
2.新建六个文件夹,名字是每个实例代表的端口号
3.将redis.conf,和 redis.server拷贝到刚才新建的文件夹下
4.修改redis.conf配置,
daemonize yes
port 端口号
cluster-enabled yes 启动集群模式
cluster-node-timeout 5000
appendonly yes
5.cd 到新建文件夹 依次启动redis实例
6.安装ruby 和一些 其他的包,还有rubygems
7.进入redis安装目录cd src 执行./redis-trib.rb create--replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1 7004 127.0.0.1:7005
建立集群成功
3.常见问题
单线程的redis为什么这么快
4.解决方案
(一)纯内存操作
(二)单线程操作,避免了频繁的上下文切换
(三)采用了非阻塞I/O多路复用机制
5.编码实战
6.扩展思考
槽(slot)的基本概念
redis存取key的时候,都要定位相应的槽(slot)。
Redis 集群键分布算法使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现: 一个 Redis 集群包含 16384 个哈希槽(hash slot), 它们的编号为0、1、2、3……16382、16383,这个槽是一个逻辑意义上的槽,实际上并不存在。redis中的每个key都属于这 16384 个哈希槽的其中一个,存取key时都要进行key->slot的映射计算。
7.参考文献
参考:
https://www.cnblogs.com/hjwublog/p/5681700.html#autoid-2-8-0
https://blog.csdn.net/tomcatAndOracle/article/details/80305947
https://www.cnblogs.com/rjzheng/p/9096228.html
8.更多讨论
感谢大家观看
BY : 鲁伯良