What、How、When、How and index
(什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?)
小课堂
分享人:辛家印
1.背景介绍
2.知识剖析
3.常见问题
4.解决方案
5.编码实战
6.扩展思考
7.参考文献
8.更多讨论
1.背景介绍
索引是什么
索引是对数据库表中一个或多个列的值进行排序的结构
索引可以做什么
索引可以加快检索表中数据,亦即能协助信息搜索者尽快的找到符合限制条件的记录ID的辅助数据结构
2.知识剖析
索引分类
普通索引:仅加速查询
唯一索引:加速查询、列值唯一(可以有null)
主键索引:加速查询、列值唯一(不可以有null)、表中只有一个
组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于同时使用多条单列索引
全文索引:对文本的内容进行分词,进行搜索
索引方式
Hash、B-Tree、B+Tree、RTree
建索引的几点原则
1.选择唯一性索引
唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。 例如,学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可以很快的确定某个学生的信息。 如果使用姓名的话,可能存在同名现象,从而降低查询速度。
2、限制索引的数目
索引的数目不是越多越好。每个索引都需要占用磁盘空间, 索引越多,需要的磁盘空间就越大。修改表时,对索引的重构和更新很麻烦。 越多的索引,会使更新表变得很浪费时间。
3、尽量使用数据量少的索引
如果索引的值很长,那么查询的速度会受到影响。 例如,对一个CHAR(100)类型的字段进行全文检索需要的时间肯定要比对CHAR(10)类型的字段需要的时间要多。
4、尽量使用前缀来索引
如果索引字段的值很长,最好使用值的前缀来索引。 例如,TEXT和BLOG类型的字段,进行全文检索会很浪费时间。如果只检索字段的前面的若干个字符,这样可以提高检索速度。
5、删除不再使用或者很少使用的索引
表中的数据被大量更新,或者数据的使用方式被改变后, 原有的一些索引可能不再需要。数据库管理员应当定期找出这些索引, 将它们删除,从而减少索引对更新操作的影响。
6、最左前缀匹配原则,非常重要的原则。
mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配, 比如a 1=”” and=”” b=”2” c=”“> 3 and d = 4 如果建立(a,b,c,d)顺序的索引, d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
3.常见问题
1、索引是怎样加快效率的?
在没有索引的情况下,数据库查找数据的时候会进行全盘扫描来寻找需要的数据, 而索引将经常需要查询的数据单独建立了有序的结构,从而提高了效率
2、不同引擎有什么区别?
没有最好的引擎,只有最适合的引擎。
ISAM:读取操作的速度很快,不支持事务处理,不能在表损坏后恢复数据。
MyISAM:读取操作更快,不支持事务,不能在表损坏后恢复数据。
InnoDB:慢很多,但是支持事务处理和外来键。
4.解决方案
确定需求后在决定引擎
MyISAM:
(1)做很多count 的计算;
(2)插入不频繁,查询非常频繁;
(3)没有事务。
InnoDB:
(1)可靠性要求比较高,或者要求事务;
(2)表更新和查询都相当的频繁,并且表锁定的机会比较大的情况指定数据引擎的创建
5.编码实战
多大的数据量下建索引会有性能的差别
6.扩展思考
1、Hash(类似HashMap)
1、使用特定的哈希函数将索引列中的值生成哈希码 hashcode ,不同的值生成的哈希码不一样
2、哈希索引将所有的哈希码和指向每个数据行的指针保存到索引中
3、如果生成的哈希码是一样的,则在那一行生成链表
4、使用了查询语句后,引擎检测使用了索引,然后会将值转换成哈希码,找到对应的索引中的哈希码,最后取出数据对比,以确保是要查找的行
例子:现有如下一个表
有7为学生及相应的得分,其中有3位重名
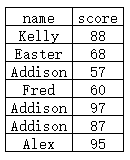
在姓名列建立Hash索引
在姓名列建立Hash索引
假设有这样的哈希函数F(),他返回这样的值
(都是假设数据,并非真实数据)

那么建立的Hash索引数据结构如下

Hash索引数据结构如下
每个槽的编号是排序的,但是数据行不是
相同的姓名(Addision)生成的哈希码是相同的,将会以链表方式解决
假如现在要查询 select score from table where name = 'Fred' ;
MySQL会先计算 'Fred' 的哈希值,即 f( ' Fred ' )=8464
然后使用该值寻找对应的槽,然后就找到对应的指针“指向第4行的指针”
最后会到第4行比对name是否是 ' Fred ' ,确保是要查找的行,输出:60
限制:
1、哈希索引不存储字段值,不能用来做覆盖索引
2、哈希索引数据不是按照索引值排序的,无法用于排序
3、哈希索引是按照索引列全部内容进行计算哈希值的,所以不支持范围查找
4、哈希冲突多的话,效率会受影响,不稳定,存储引擎必须遍历链表中的所有行指针,逐行对比知道找到相应的行。同样的删除也会受影响
二叉树
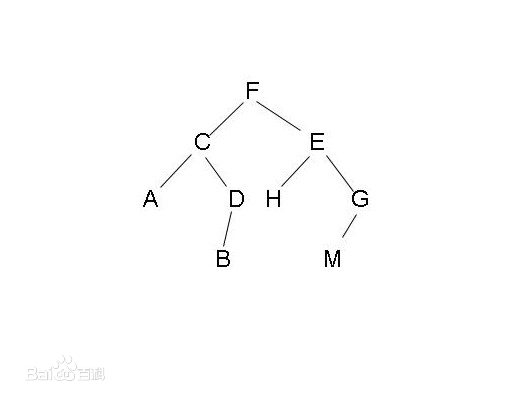
一个简单的二叉树结构
以此为例,假如找H,那么要先找到F(代表该二叉树)
然后指向E,最后指向H
2、B-Tree平衡多路二叉树
如图是一个3阶B-Tree
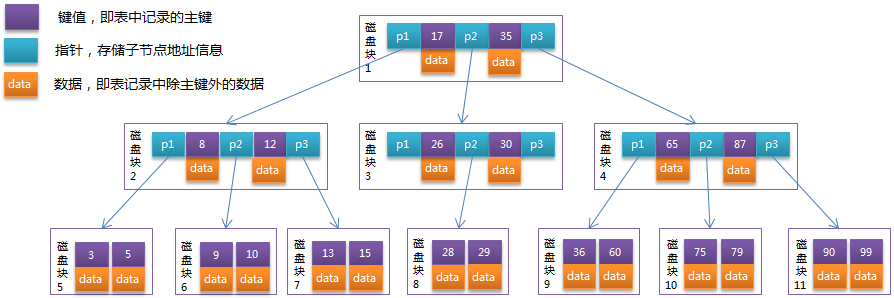
系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么取什么。
假设现在有如图这样一个B-Tree索引,找键10携带的数据
1、根据根节点找到磁盘块1,读入内存。【I/O操作第1次】
2、比较关键字10在小于17区间,找到磁盘块1的指针P1。
3、根据P1指针找到磁盘块2,读入内存。【I/O操作第2次】
4、比较关键字10在区间(8,12),找到磁盘块2的指针P2。
5、根据P2指针找到磁盘块6,读入内存。【I/O操作第3次】
6、在磁盘块6中的关键字列表中找到关键字10。
分析上面过程,发现需要3次磁盘I/O操作,和3次内存查找操作由于内存中的关键字是一个有序表结构,
可以利用二分法查找提高效率。而3次磁盘I/O操作是影响整个B-Tree查找效率的决定因素,
但是该表中查询数据最多只使用3次I/O操作,但是相对于普通二叉树,和平衡二叉树,B-Tree缩减了节点个数,
使每次磁盘I/O取到内存的数据都发挥了作用,从而提高了查询效率。
3、B+Tree
只有叶子记录关键字记录的指正,非叶子节点只进行数据索引,所有数据地址必须要到叶子节点才能获取到,所以每次数据查询的次数都一样。
如图是一个3阶B+Tree
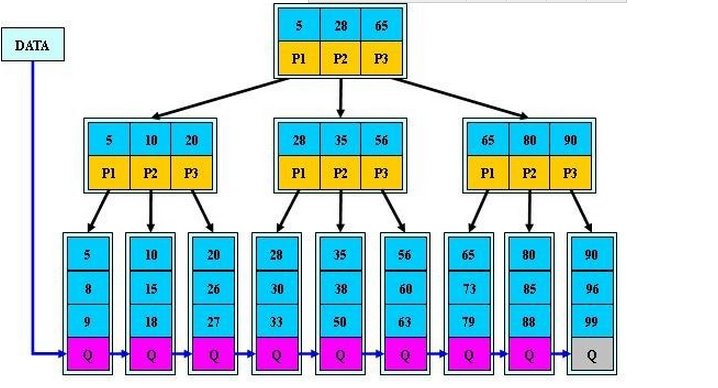
假设现在有如图这样一个B+Tree索引,找键63携带的数据
1、根据根节点找到磁盘块,读入内存。【磁盘I/O操作第1次】
2、比较关键字63在区间[28,65),找到磁盘块的指针P2。
3、根据P2指针找到磁盘块,读入内存。【磁盘I/O操作第2次】
4、比较关键字63在区间[56,65),找到磁盘块的指针P3。
5、根据P3指针找到磁盘块,读入内存。【磁盘I/O操作第3次】
6、在磁盘块中的关键字列表中找到关键字63。
分析上面过程,发现不管查找哪个数据都需要3次I/O操作,
所以查询速度稳定,查询速度非常接近二分法。
另外B+Tree中非叶子节点不需要保存关键字记录的指针,
每个节点能保存的关键字大大增加,所以B+Tree比B-Tree更有效率、更稳定。
4、聚集索引(InnoDB引擎)
聚集索引的主索引的叶子节点存储的就是数据本身,辅助索引的叶子节点存储的是对应数据的主键键值。
在指定主键时会建立主索引
每个主键都携带着数据行,找到主键即找到了数据行
如果没有指定主键,系统内部会自动生成一个“行id”,
但是无法操作该数据,然后生成一个包含该id的聚集索引
所以系统中总会有且仅有一个聚集索引。
聚集索引中的索引结构
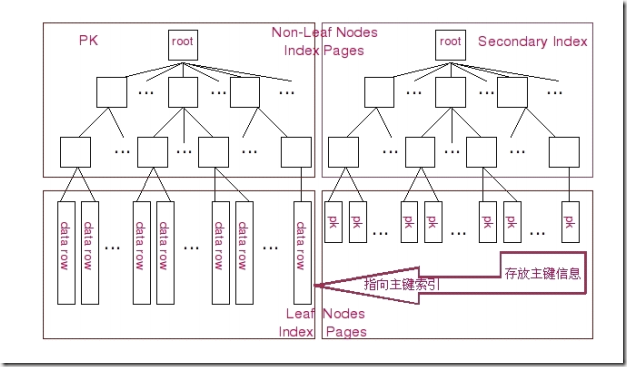
左边是主索引,右边是辅助索引
聚簇索引的数据是根据主键的顺序保存。
如果只需要查找索引的列,就尽量不要加入其它的列,这样会提高查询效率。
5、非聚集索引(MyISAM引擎)
非聚集索引结构
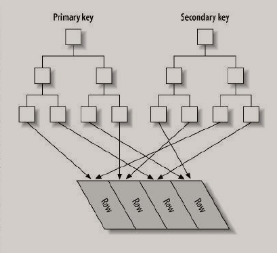
非聚集索引中的主索引和辅助索引几乎是一样的,主索引不允许重复和空值,他们的叶子都存储着键值对应的数据的物理地址
所以非聚集索引中的索引和数据是分开存储的
非聚簇索引中的数据是根据数据的插入顺序保存。
7.参考文献
1. 百度百科:数据库索引2.How does InnoDB behave without a Primary Key?
3.从Mysql源代码角度分析一句简单sql的查询过程
4.BTree和B+Tree详解
5.为什么索引可以加速查询?
6.哈希索引
7.btree索引和hash索引的区别
8.更多讨论
鸣谢
感谢观看,如有出错,恳请指正