dom的操作
分享人:周能
目录
1.背景介绍
2.知识剖析
3.常见问题
4.解决方案
5.编码实战
6.扩展思考
7.参考文献
8.更多讨论
一、背景介绍
什么是dom
DOM是针对于HTML和XML文档的一个API(应用程序编程接口)。是W3C组织推荐的处理可扩展标志语言的标准编程接口。在网页上,组织页面(或文档)的对象被组织在一个树形结构中,用来表示文档中对象的标准模型就称为DOM。
当网页被加载时,浏览器会创建页面的文档对象模型
在DOM中,可以将任何HTML或者XML的文档描绘成一个由多层节点构成的结构
二、知识剖析
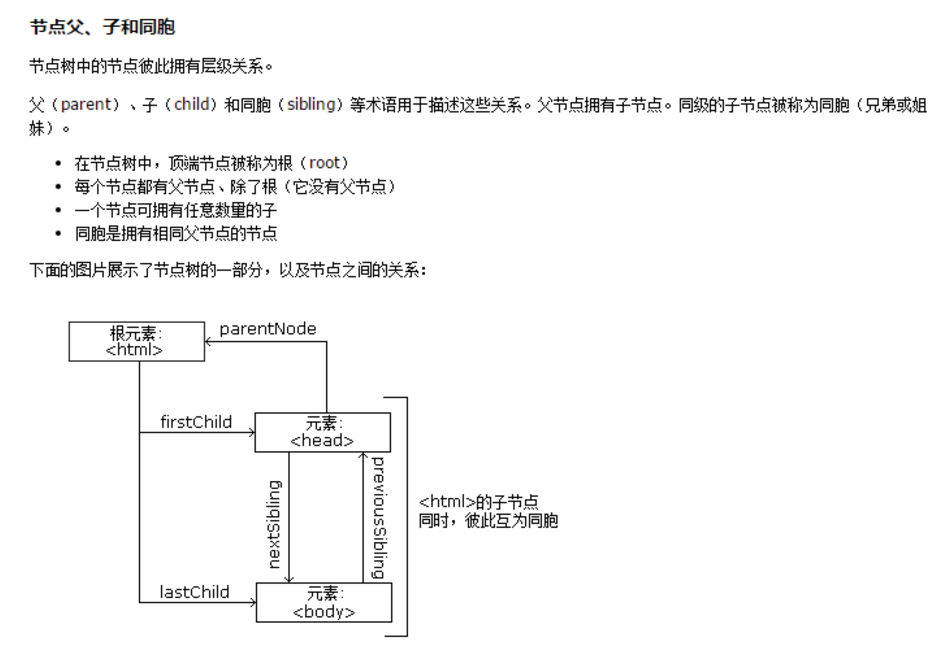
获取dom节点
1.id查找 document.getElementById()
2.class查找 document.getElementsByClassName()
3.标签查找 document.getElementsByTagName()
注意事项
ID不能重名,如果ID重复,只能取到第一个。
获取元素节点时,必须等到DOM树加载完成后才能获取。
通过class和标签获取到的节点为数组格式,操作时必须取到其中的每一个元素(数组下标),才能进行操作,而不能直接对数组进行操作。
节点操作
1. .childNodes: 获取当前节点的所有子节点(包括元素节点和文本节点)。
.children: 获取当前节点的所有元素子节点(不包含文本节点)。
3 .parentNode: 获取当前节点的父节点。
设置文本节点
1.innerHTML: 取到或设置一个节点中的HTML代码。
2.innerText: 取到或设置一个节点中的文本,不能设置HTML代码。
新增节点
appendChild(): 在父节点的内部最后,插入一个新节点。
.cloneNode(true): 克隆一个节点。
删除、替换节点
1.removeChild(): 从父节点中,删除指定子节点。
2.replaceChild(): 从父节点中,用新节点替换老节点。
三、常见问题
cloneNode(true): 克隆节点true有什么用
四、解决方案
传入true表示克隆源节点以及源节点的所有子节点;
传入false或不传,表示只克隆当前节点,而不克隆子节点。
五、编码实战
六、拓展思考
七、参考文献
八、更多讨论
鸣谢
感谢大家观看
BY : 周能